自从云计算的概念被提出,不断地有IT厂商推出自己的云计算平台。Amazon的AWS、微软的Azure和IBM的蓝云等都是云计算的典型代表,但它们都是商业性平台,对于想要继续研究和发展云计算技术的个人和科研团体说,无法获得更多的了解,Hadoop的出现给研究者带来了希望。本章将重点介绍Hadoop的HDFS、MapReduce和 jHBase,以及Hadoop的具体应用。
Hadoop简介
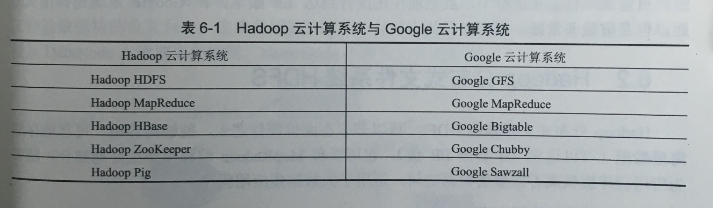
Hadoop是Apache开源组织的一个分布式计算框架,可以在大量廉价的硬件设备组成的集群上运行应用程序,为应用程序提供了一组稳定可靠的接口,旨在构建一个具有高靠性和良好扩展性的分布式系统。随着云计算的逐渐流行,这一项目被越来越多的个人和企业所运用。Hadoop的核心是HDFS、MapReduce和HBase,它分别是Google云计算最核心技术GFS、MapReduce和Bigtable的开源实现(表6-1 )。
Hadoop源于另外两个开源项目Lucene和Nutch,它们是一脉相承的关系。Lucene是一个用Java开发的开源高性能全文检索工具包,可以很方便地嵌入到各种实际应用中,实现搜索/索引功能;Nutch是第一个开源的Web搜索引擎,它在Lucene的基础上增加了网络爬虫、Web相关的一些功能及一些解析各类文档格式的插件等,还包含一个分布式文件系统用于存储数据。从Nutch 0.8.0开始,将其中实现分布式文件系统和MapReduce算法的代码独立出来,形成了一个新的开源项目,这就是HadooP。
Hadoop丰要由以下几个子项目组成。
(1)Hadoop Common:即原来的Hadoop Core。这是整个Hadoop项目的核心,其他Hadoop子项目都是在Hadoop Common的基础上发展的。
(2)Avro: Hadoop的RPC(远程过程调用)方案。
(3)Chukwa:—个用来管理大型分布式系统的数据采集系统。
(4)HBase:支持结构化数据存储的分布式数据库,是Bigtable的开源实现。
(5)HDFS(Hadoop Distributed File System):提供髙吞吐量的分布式文件系统,是GFS的开源实现。
(6)Hive:提供数据摘要和查询功能的数据仓库。
(7)MapReduce:大型数据的分布式处理模型,是Google的MapReduce的开源实现。
(8)Pig:是在MapReduce上构建的一种高级的数据流语言,它是Sawzall的开源实现。Sawzall是一种建立在MapReduce基础上的领域语言,它的程序控制结构(如if、 while等)与C语言无异,但它的领域语言语义使它完成相同功能的代码比MapReduce的C++代码简洁得多。
(9)ZooKeeper:用于解决分布式系统中一致性问题,是Chubby的开源实现。
在这些子项目中,Pig最初是由Yahoo的网格部门开发的,后来捐献给了Apache基金会。Awo和Chukwa刚加入不久,目前还不是很成熟。从实现的功能来看,Hadoop几乎就是Google的一个“翻版”,几乎每个子项目都是Google某项技术的开源实现。
除了是开源的之外,Hadoop还有很多优点。
(1)可扩展。不论是存储的可扩展还是计算的可扩展都是Hadoop的设计根本。
(2)经济。Hadoop可以运行在廉价的PC上。
(3)可靠。HDFS的备份恢复机制及MapReduce的任务监控机制保证了分布式处理的可靠性。
(4)高效。分布式文件系统的高效数据交互实现及MapReduce结合Local Data处理的模式,为高效处理海量的信息做了基础准备。
目前此项目正在进行中,虽然现在还没有到达1.0版本,和Google系统还有很大差距,但是前景非常好,值得我们关注。
